UIDAI Documentation
Last updated January 19, 2026
Aadhaar is the world's largest biometric ID system. This documentation outlines the technical synchronization and analytics engine built to transform raw governmental data into policy-ready insights.
Get started with the Engine
The core objective is to handle raw enrolment and update data via a clean, consistent, and policy-ready pipeline. This enables accurate district-level analysis of societal trends.
Problem Statement
How can raw Aadhaar data be transformed into a consistent dataset that enables accurate analysis to help in analyzing societal trends across India?
Technical Approach
We use a decentralized, automated pipeline to collect, clean, and visualize data from official UIDAI sources.
System Architecture
The following diagram visualizes the data flow from Government APIs to the final Intelligence Report.
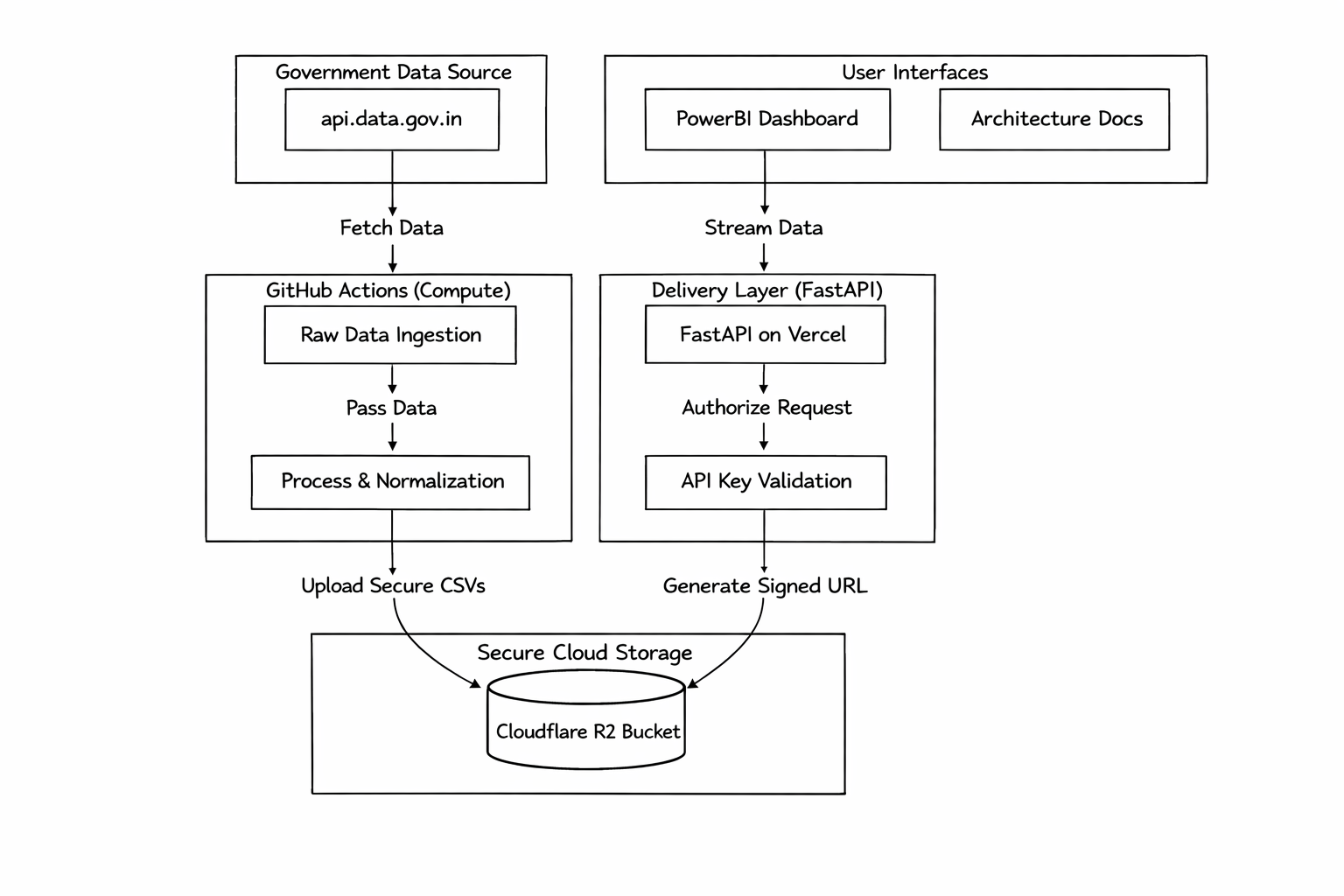
Dataset Lifecycle
The system integrates three high-granularity datasets, collectively representing the identity lifecycle of an Indian citizen.
1. Enrolment Data
Captures new generation activity across age groups. This is the primary entry point for new residents into the ecosystem.
2. Demographic Updates
Tracks mobility and profile maintenance including name, address, gender, and mobile updates.
3. Biometric Updates
Records fingerprint and iris transactions, highlighting mandatory child updates which are critical for identity persistence.
Direct Data Access
You can programmatically access both normalized and raw datasets using our API. Authentication is required.
Supported Datasets:
Processed: master, biometric, enrollment, demographic
Raw: biometric, enrollment, demographic
Post-Integration Methodology
Our processing engine ensures zero silent data loss through a strict consensus framework.
Integrity Audit
- Source Attribution Tagging
- Horizontal Consolidation
- Row count verification
Strict Consensus
- Majority-Vote Logic
- PIN-based Geo Validation
- Quarantine of Ambiguity